上观新闻2024年11月14日发布:斯坦福团队研究:AI生成的科研想法比人类专家更有创意,但无法替代人类
作者:Sofía | 责任编辑:Admin
本次大会汇集了来自全球各地的科技领袖,共同探讨未来科技趋势...
【2024年澳门特马今晚开码】 |
【新奥精准资料免费提供】 |
| 【新奥天天免费资料公开】 |
| 【2024澳门天天六开彩开奖结果】 |
| 【新澳门精准全年资料免费】 |
| 【新澳正版资料勉费大全】 |
| 【新澳精选资料免费提供开】 |
| 【二四六香港资料期期中准】 |
| 【新奥天天免费资料单双中特】 |
| 【新澳门历史记录查询最近十期】 |
对于大语言模型(Large Language Model,LLM)而言,提出新的想法并不难,真正难的是,提出那些新颖且有价值的想法。
如同 Wolfram 所说:“实际上,做出原创性的工作是非常简单的,你只需选择一堆随机数。那些随机数序列非常出人意料、有创意、也很有独创性,但这对我们来说,并没有太大意义,我们真正感兴趣的是那些有原创性而‘有趣’的东西。”
毕竟,让用户吃胶水和石头的想法不也是很新颖的吗?

图丨此前谷歌发布的 AI 搜索曾产生一系列的谎言和错误信息,包括建议在披萨食谱中使用胶水以及摄入石头来补充营养等,引起轩然大波(来源:New York Times)
因此,要评估 AI 想法的新颖性,必须要附带一个额外条件:它们至少要与人类专家提出的想法水平相当。
但目前,还没有相关研究证明 LLM 系统能够生成达到专家水平的新颖想法。
于是,为了弥补这方面研究的缺失,探明 AI 在科学研究中的创新潜力,来自斯坦福大学的研究团队展开了一项研究,对当前 LLM 是否能够生成人类专家级的创新性研究想法进行了探究。

图丨相关论文(来源:arXiv)
为了进行对比,团队招募了 104 位 NLP 研究者,让其中 49 位写下创新研究想法,然后再让 79 位专家对 LLM 和人类给出的思路进行盲测(其中有 24 位也参与了想法的撰写,但他们不会审查自己的想法)。
而与他们对垒的主干模型则是 claude-3-5-sonnet-20240620,同时结合了 RAG 论文检索、创意生成和创意排名等功能,以更好地产出科研思路。
实验设置的研究问题与七个主题相关:偏见、编程、安全性、多语言、事实性、数学和不确定性,而最后的评估则主要围绕新颖度、令人兴奋的程度、可行性和有效性四个维度展开。
先说主要结论,与人类专家的想法相比,LLM 生成的想法更为新颖(p < 0.05),但在可行性方面则相对逊色。
那么实验具体是如何来展开的呢?
在设置好问题后,人类专家与 LLM 会生成与之相关的研究思路,而这些思路需要被书写出来并用于交流时,其价值才能被评估,然而,这一过程本身却带来了额外的挑战。比如,人类研究人员在表达自己的研究设想时,往往会通过更丰富的例子和详细的实施方案来增强说服力,这无形中增加了评估的复杂性。
为了解决这个问题,研究者设计了一套模板,让所有人按照同样的格式提交创意提案,包括标题、问题陈述、方法建议等内容。同时,他们还使用了一种风格标准化工具,将所有提案转换成统一的写作风格,避免了个人风格对评分的影响。

图丨风格标准化工具(来源:arXiv)
另一方面,对研究思路的审查也同样不可避免地具有主观性。因此,研究团队参考一些 AI 顶会的评审,设计了一份详细的审查表,明确了所有评估标准,力求使评估过程更加标准化。
除了给出总体评分外,还设定了四个具体的评估指标:新颖性、吸引力、可行性和预期效果。评审员需要根据指标给出 1-10 的分数,并附上理由说明。
除了人类专家提出的与 AI 自动筛选出(AI Ideas)的想法,研究者还从 AI 生成的想法中手动筛选出了一些最为优秀的(AI Ideas + Human Rerank),以评估 AI 创意的最大潜力。
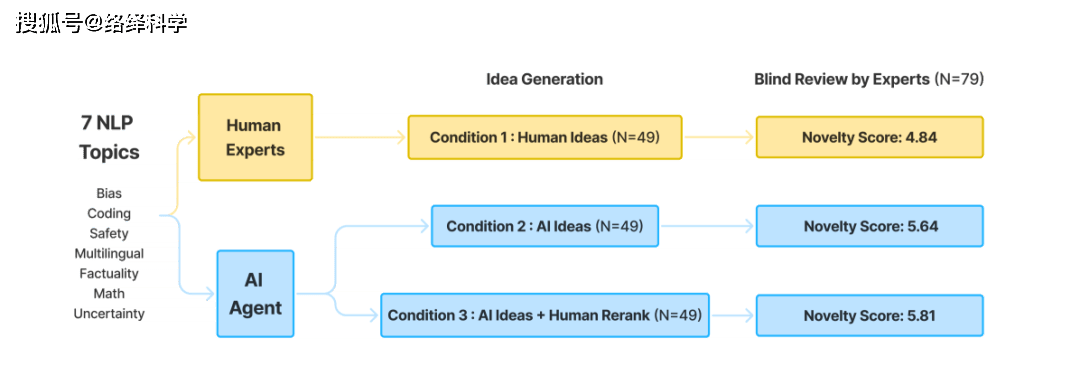
图丨实验流程图(来源:arXiv)
最终的结果如上所述,无论是 AI Ideas 还是 AI Ideas + Human Rerank,都在新颖性方面显著优于人类专家的想法(p < 0.01)。在可行性方面,则稍有逊色。而在激动人心(excitement)评分上,AI 生成的思路的优势更为明显(p < 0.05)。
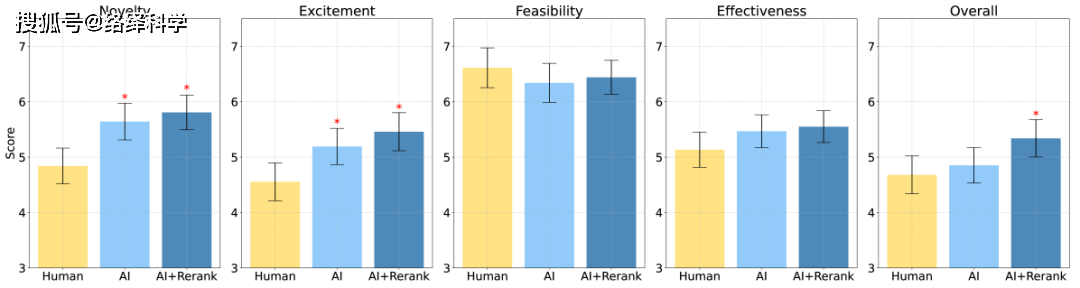
图丨最终的评审结果(来源:arXiv)
即使是由人类重新排序的 AI 思路,其整体得分也超过了人类专家提出的想法(p < 0.05)。至于有效性方面,AI 生成的思路得分略高于人类思路,但差异不大。
不过,需要注意的是,尽管 LLM 有能力生成大量的创意,但这些创意的多样性有限。团队分析了每个主题下生成的 4000 个想法,发现新想法中非重复的比例逐渐下降,最终趋于稳定。4000 个想法中只有200个是非重复的。
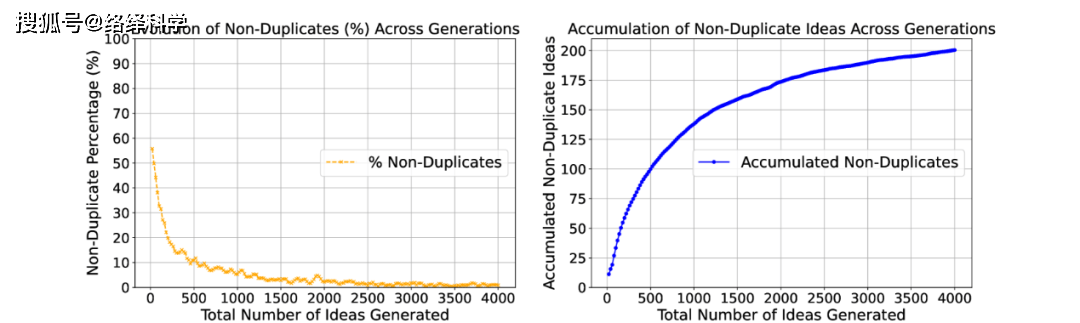
图丨新生成想法中非重复想法的百分比;随着AI不断生成新想法,累积的非重复想法(来源:arXiv)
而且,在评估创意的能力上,LLM 也远不如人类专家。例如,表现最好的 LLM 评估者——Claude-3.5 成对排序器,其准确率只有 53.3%,而人类评审员之间的评分一致性为 56.1%。
这么看来,AI 的确有能力提出很多有价值的新颖想法,或许在很多时候能给我们带来意想不到的惊喜,但至少目前为止,AI 科学家,尚未成为现实。
只有人类与 AI 协作起来,才能达到 1+1>2 的效果,而进一步探索如何优化这种协作方式,也是研究团队未来的目标之一。
参考链接:https://arxiv.org/abs/2409.04109
本文内容不代表平台立场,不构成任何投资意见和建议,以个人官网/官方/公司公告为准。返回搜狐,查看更多
责任编辑:
| 【7777788888澳门开奖2023年一】 | 【澳门天天免费资料大全192.1】 | 【管家婆一肖一码100%准确】 | 【新澳门免费资料大全精准】 | 【澳门六开彩天天正版澳门在线】 | 【新澳门三肖中特期期准】 | 【澳门天天免费精准大全】 | 【新澳正版资料免费大全】 |
推荐文章

重庆冬季旅游最佳去处 ,懒人出行直接照搬就好
那么实验具体是如何来展开的呢?...

掘金沙特:中国医药健康创新企业出海新乐土
即使是由人类重新排序的 AI 思路,其整体得分也超过了人类专家提出的想法(p < 0....

求牛蛙的心理阴影面积! 福建, 小孩姐一手抓着青蛙霸气撸串
对于大语言模型(Large Language Model,LLM)而言,提出新的想法并不难,真正难的是,提出那些新颖且有价值的想法。...

《克莱重回勇士主场:英雄归故地,羁绊似金坚》
图丨实验流程图(来源:arXiv) ...
最新评论
陈安立 2024-11-13 15:21
只有人类与 AI 协作起来,才能达到 1+1>2 的效果,而进一步探索如何优化这种协作方式,也是研究团队未来的目标之一。
IP:73.44.4.*
罗兰德·杨 2024-11-13 23:13
但目前,还没有相关研究证明 LLM 系统能够生成达到专家水平的新颖想法。
IP:73.10.3.*
保罗·博纳切利 2024-11-13 22:18
于是,为了弥补这方面研究的缺失,探明 AI 在科学研究中的创新潜力,来自斯坦福大学的研究团队展开了一项研究,对当前 LLM 是否能够生成人类专家级的创新性研究想法进行了探究。
IP:74.61.5.*